
Setting Up a Flow Node
First you'll need to provision a machine or virtual machine to run your node software.
Hardware Requirements
The hardware your Node will need varies depending on the role your Node will play in the Flow network. For an overview of the differences see the Node Roles Overview.
| Node Type | CPU | Memory | Disk |
|---|---|---|---|
| Collection | 2 cores | 16 GB | 200 GB |
| Consensus | 2 cores | 16 GB | 200 GB |
| Execution | 16 cores | 128 GB | 2 TB |
| Verification | 2 cores | 16 GB | 200 GB |
| Access | 2 cores | 16 GB | 200 GB |
Note: The above numbers represent our current best estimate for the state of the network. These will be actively updated as we continue benchmarking the network's performance.
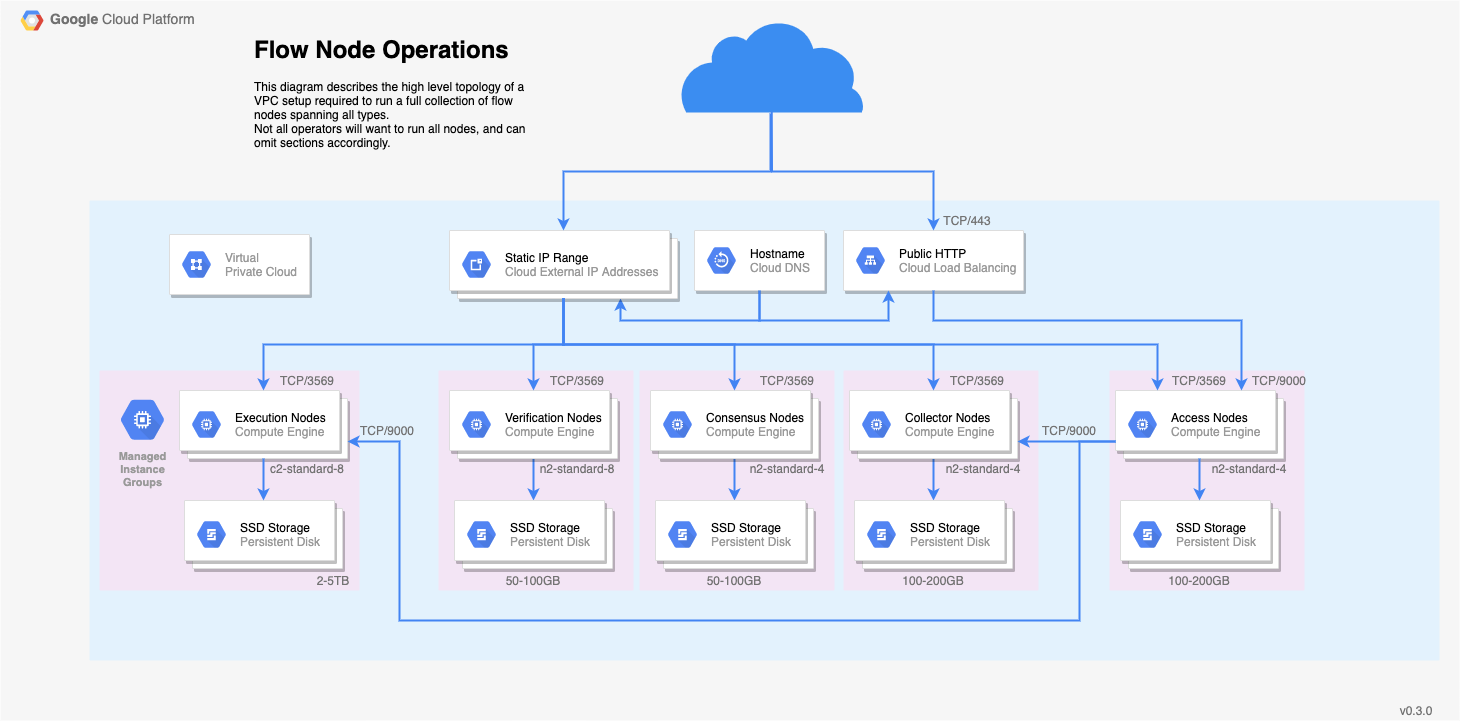
Networking Requirements
Most of the load on your nodes will be messages sent back and forth between other nodes on the network. Make sure you have a sufficiently fast connection; we recommend at least 1Gbps, and 5Gbps is better.
Each node will require either a static IPv4 address or a fixed DNS name. Either works, and we'll refer to this more generally as your 'Node Address' from here on out.
Your firewalls must expose TCP/3569 for Node communication. If you are running an Access Node, you must also expose the GRPC port 9000.
Operating System Requirements
The Flow node code is distributed as a Linux container image, so your node must be running an OS with a container runtime like docker or containerd.
The bootstrapping scripts we'll use later are compiled binaries targeting an amd64 architecture, so your system must be 64-bit. Some of these scripts are bash based hence a shell interpreter that is bash compatible will also be needed.
Flow also provides systemd service and unit files as a template for installation, though systemd is not required to run Flow.
For the remainder of this guide, we cover the most simple case, a single node being hand deployed. This should give you a good sense of what's needed, and you can modify to suit your needs from there.
The Flow team has tested running nodes on Ubuntu 18.04 and GCP's Container Optimized OS, which is based on Chromium OS. If you are unsure where to start, those are good choices.
Setup Data Directories & Disks
Flow stores protocol state on disk, as well as execution state in the case of execution nodes.
Where the data is stored is up to you. By default, the systemd files that ship with Flow use /var/flow/data.
This is where the vast majority of Flow's disk usage comes from, so you may wish to mount this directory on a separate disk from the OS.
The performance of this disk IO is also a major bottleneck for certain node types.
While all nodes need to make use of this disk, if you are running an execution node, you should make sure this is a high performing SSD.
As a rough benchmark for planning storage capacity, each Flow block will grow the data directory by 3-5KiB.
Pull the Flow Images
The flow-go binaries are distributed as container images, and need to be pulled down to your host with your image management tool of choice.
Replace $ROLE with the node type you are planning to run. Valid options are:
- collection
- consensus
- execution
- verification
- access
# Docker
docker pull gcr.io/flow-container-registry/${ROLE}:alpha-v0.0.1
# Containerd
ctr images pull gcr.io/flow-container-registry/${ROLE}:alpha-v0.0.1",
Set Your Node to Start
Your nodes will need to boot at startup, and come back to life if they crash.
If you are running systemd you can use the service files provided by flow-go. Find them in the Flow Go
mv ~/flow-${ROLE}.service /etc/systemd/system/.\n\nsystemctl enable flow
If you are using some other system, you need to ensure that the Flow container is started, and the appropriate key directories are mounted into the container.
The systemd files pull runtime setting from /etc/flow/runtime-config.env and any .env files under /etc/flow/conf.d. Examples of these files are also available in the github repo. You will need to modify the runtime config file later.